Unicode notes
Lacewing Blue, as of build 95+ of Blue Client and build 26+ of Blue Server, includes Unicode messaging.
Unicode is a character set used by Lacewing Blue in order to exchange messages that can feature any language, and any type of special character, such as a Right-To-Left modifier, emojis, etc.
Without Unicode, anyone not in a Latin-based country, for example anyone in an Asian or Arabic-speaking country, will not be able to communicate in their native language over Lacewing.
Unicode is implemented automatically for you, and is (to the extent it can be), backwards-compatible with non-Unicode (ANSI) Lacewing.
The maximum you will need to be concerned about is measuring bytes and code lengths, which are handled by the UTF-8 expressions (see in Blue Client and Server).
For a more detailed explanation on Unicode, read below.
Character sets used in Fusion
To understand how characters work, you will need an understanding of bits and bytes, which is covered under the Types of messages topic. Read that before proceeding.
Now you've read that and understand how a byte stores a number from 0 to 255 inclusive, and you should also know that the number of a byte is translated to text according to an internal table, called the "character set".
You will encounter two character sets used by normal Fusion and extensions: ANSI and UTF-16.
ANSI
The ANSI character set is half of the ASCII character set, and the other half dependent on the system language. Most English Windows systems will use Windows-1252, but other languages use different ones, for the same byte range.
- ASCII is byte range 0 to 127, always the same everywhere.
You can see the table of the ASCII characters here. - ANSI is byte range 128-255.
How bytes 128-255 are displayed depends on the code page used when translating.
For example, Greek Windows and English Windows use different code pages.
That is why it's a bad idea to use ANSI, particularly in a multiplayer where sender and receiver clients could be in different OS languages, as the meaning of 128+ ANSI characters may be misinterpreted due to difference in the sending client's and receiving client's code pages.
See a demonstration of misinterpretation under Font display below.
As a side note: code pages are frequently called the misnomer "ANSI code page", or "extended ASCII code page", but most correctly, Windows code pages.
UTF
UTF-XX is Unicode Text Format, and the XX number following is the number of bits used to encode the smallest possible character.
All UTFs are designed to be the same on every OS, regardless of OS language setting.
Fusion runtime
- Extensions in Fusion\Extensions folder use ANSI when talking with Fusion.
- Extensions in Fusion\Extensions\Unicode folder use UTF-16 when talking with Fusion.
Fusion extension compatibility
Windows dates back to before UTF times, so Windows OS was initially ANSI as well.
Fusion 2.0 was originally released as ANSI, producing ANSI apps, and then later a Unicode add-on was released, producing Unicode apps.
Fusion 2.5 has the Unicode add-on built in, so it always produces Unicode apps.
The Fusion Unicode add-on will prefer an Unicode extension over an ANSI one, even if the ANSI one was modified more recently. Fusion will attempt to convert between ANSI and Unicode so to allow ANSI extensions to still be used in Unicode apps, but as ANSI uses the system's language, it will often not convert correctly.
This is particularly noticeable in scenarios where you interact with external objects, e.g. if you attempt to delete a file with a Unicode filename, using an ANSI object.
Other Unicode terms
To understand how characters work, you will need an understanding of bits and bytes, which is covered under the Types of messages topic.
Read about those before reading the list below, or it will make no sense.
Here are Unicode terms you may find useful:
- A code unit is a single unit of storage that may be part of a code point, or a full code point. In UTF-8, every code unit is 8 bits (1 byte). In UTF-16, every code unit is 16 bits (2 bytes).
- A code point is an entry in a character set. In UTF-8, 1-4 code units may be used for a single code point. In UTF-16, 1-2 code units may be used.
- Code points can be combined into one displayed symbol, called a "grapheme". This is useful when adding two displays on top of each other; for example, "a" and "ä" are both graphemes.
"ä" can be written in Unicode as a single code point "ä", or as two code points, a + ̈ , where the two-dots is a "combining" diaeresis.
For a more extreme example, look for "zalgo text" on Google. - Making sure Unicode uses the least amount of code points is called Unicode normalization. This is done automatically in Lacewing, and in most OS controls.
- A "glyph" is an entry in a font file, and the font can choose how to render code points; for example, it may take the one-code-point ä and turn it into a + ̈ .
- A "character" is an term ambiguously used for several of the above things, but usually referring to a code point or grapheme.
For perhaps a better definition of these terms, see here.
Font display
While Unicode will always be read the same way on every system, this does not mean one font can display all of Unicode's ~150,000 characters, as fonts are restricted to ~65,500 characters on Windows.
However, in rich text controls like Rich Edit object, Windows will switch to a different font if it can't display a given character. This may result in font changes, such as this:

(This shows a Rich Text object switching font from Arial font to SimSun font automatically, as SimSun supports Chinese/Japanese symbols. Note it is back to Arial on the next line, but the rest of the line with the special character looks odd.)
In non-rich text controls, such as Editbox, you may get your character drawn with the "replacement character" of that font. This can be a box, like 𐀀, or a ? character, or a diamond.
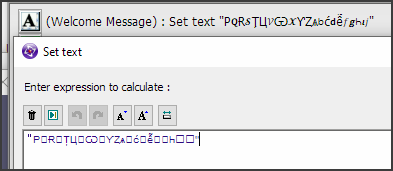
The same text, displayed improperly by one font, and correctly by another.

Other replacement characters.
Try to use a more compatible font, such as Arial Unicode MS, Noto Sans, etc. There are several free fonts hosted by Google, but remember the 65,500 cap per font still applies regardless.
Lacewing's internal character set, UTF-8
Lacewing Relay uses ANSI, causing the problems above.
Lacewing Blue however, uses the smaller form of UTF, called UTF-8. This has three benefits:
- UTF-8 starts with ASCII (like ANSI does), so it is partially readable by ANSI apps and extensions. More on that below.
- UTF-8 is half the size of UTF-16 for the same content, in most scenarios.
- UTF-8 is now recommended to be used everywhere for Unicode.
The second half of UTF-8 (and following) is UTF, so is designed to be the same on every OS, regardless of language setting. UTF-8 will also never cut off early if an ANSI reader is processing the text, even if the ANSI reader cannot interpret them properly.
This is in contrary to UTF-16, which will have the first character read correctly by ANSI, and then the second character will tell ANSI to end the string:
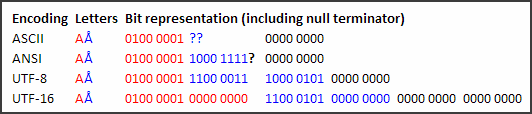
Describing the oddities in the image:
- ASCII has no entry for Å, so it can't display it at all. Chances are, it'll encode Å as a replacement character, probably a ASCII question mark, or it will strip the circle and encode as ASCII letter A.
- ANSI has an entry for Å – sometimes. When it does, the byte value may be what is shown on the image, or might be something else, depending on code page… hence the question mark.
- UTF-16's second byte of A is null. So an ANSI reader will read the A byte, then read the null byte of the A, think it's the null terminator, and stop reading.
UTF-16 of course uses a 16-bit (2-byte) null terminator, but an ANSI reader will be reading the text like ANSI, in 1-byte chunks. - In contrast to UTF-16, note that in UTF-8, an ANSI reader will read all the red and blue bytes before stopping, because the first null byte is the null terminator, same in UTF-8 as in ANSI. UTF-8 only uses a null byte for end of string, never as part of the string like UTF-16 does.
If you, for some reason, are aiming for an ANSI-compatible Unicode app, consider restricting the characters using the "Set Unicode allowlist" actions to ASCII only.
In ANSI apps, anything that is not ASCII may be distorted beyond recognition:
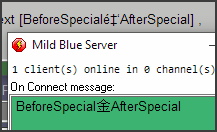
The top program in gray box shows received message read by ANSI Lacewing Relay, the bottom green box shows the original UTF-8 message.
Note that if UTF-16 was used, the ANSI client would only have read the starting "B" of the "BeforeSpecial…" message, then hit the second null byte of the UTF-16, and stopped.
Additional name limitations
The naming in Bluewing is quite strict but follows this principle: the name cannot have blank space around it, or start with something that is not a letter or number. The entire name is also limited by the server's Unicode allowlist.
Similar names cannot be used. If a user is called Calvin, no other user can call themselves [alvin, (alvin, Ca1vin, Calvín, CaIvin (uppercase i, not lowercase L), etc. Even things like Villy becoming \/illy are checked for; not every single similar scenario, but the most common ones.
The simplification means characters are merged together; for example, hyphens like math minus symbol, em dash, en dash, etc., are simplified to a single hyphen type.
These name restrictions apply to both client and channel names, including the channels created by the server or named modified by the server.
It should be noted that in default server configuration, you can still change your own casing; e.g. a client named "Jamie" could set their name to "Jamíe" or "jamie" even though other users could not.
Other limitations on name include:
- The start of the name must be punctuation, a letter, or a number, but not any whitespace*. Emojis are symbols, and so aren't allowed.
- The end of the name is more lenient and can be a symbol or a mark, but still whitespace* aren't allowed.
- All of the name, including the middle, can be anything, provided it matches the Unicode allow-list set by the server.
(the default allowlist is discussed below)
*= whitespace are any spacing characters, including spaces, tabs, line breaks, or exotic whitespace like Unicode zero-width non-joiner.
These limitations are to ensure that it is usually possible to find users by the start of their name. Most input boxes like Editbox will remove special characters like tabs or newlines.
There is a default allowlist for client and channel names, explained below.
Allowlist format
The allowlist format is comma-separated. It should not start or end with a comma. All spaces will be removed before processing begins.
You can specify:
- Single code points.
This can be as a decimal, or as a hex number starting with 0x.
For example, "49", or "0x31", or "0x0031", are all valid representations of digit one '1' character, which has a code point value of decimal 49, hex 0x31, U+0031. - Code point ranges.
Like single code points, these can be decimal or hexadecimal, and are separated by a hyphen "-". The start and end of the range are included. - Unicode categories.
The categories are defined by the Unicode organization and can be viewed both here and here. - Unicode category wildcard.
For example, all letter categories can be added by "L*", instead of listing all categories like "Ll, Lm, Lo, Lt, Lu".
Blue will do some basic tests for overlaps or repeats in your allowlist.
For performance, try to arrange your allowlist so the most used parts will be first, and thus each character will match soon.
The allowlist can be freely changed, but should be done before hosting, ideally, as the changes will not be enforced retroactively.
Default Blue Server allowlist
The Blue Server starts with a default allowlist for client and channel names, set to allow:
- All letters, numbers, and marks – mark such as the accent on é.
- space
- basic punctuation: !#$%&'()*+,-.:;<=>?@ A-Z []^_{|}~
- additional: ¿¡$£¤¥©®°
- NOT allowed, the double-quote: "
- NOT allowed: tab, newline, and other whitespace.
There is no default allowlist for received by client/server text messages.
Even if you restrict received by client/server text messages using an allowlist, binary messages that contain text will not have their text checked, as where the text in a binary message starts or stops is specific to your app's messages, and so not known by the C++ side of the server.
For checking against an allowlist manually, you can use the "Convert to UTF-8 and check against Unicode allowlist" expressions (see in Client and Server).
Note that in Blue Server, you can specify the allowlist name to reuse a currently set allowlist.